

If you come across a datastore that cant is unmountable or inaccessible, it not an easy task to remove the zombie datastore. Delete the datastore/Remove from inventory option from ESXi host won’t work.
Inaccessible datastores as shown could be caused due to a variety of factors such as –
- Hardware panic causing NFS array volumes to go into read-only
- Planned DR tests - Zerto / Veeam / Recoverpoint etc where cleanup hasn't completed well. All these mounts are usually NFS protocols.
- SDRS enabled on the NFS datastore during the "All Path Down" scenario.
- Ungraceful shutdown / Loss of storage array causing datastores paths to go dead.
Chances are more that you won’t be able to remove an inactive NFS or an ISCSI datastore during an APD situation so it’s worth, as a quick workaround, attempting these steps to see if that fixes the issue.
- Disable Storage I/O control, if possible.
- Remove the datastore from vSphere HA heartbeat.
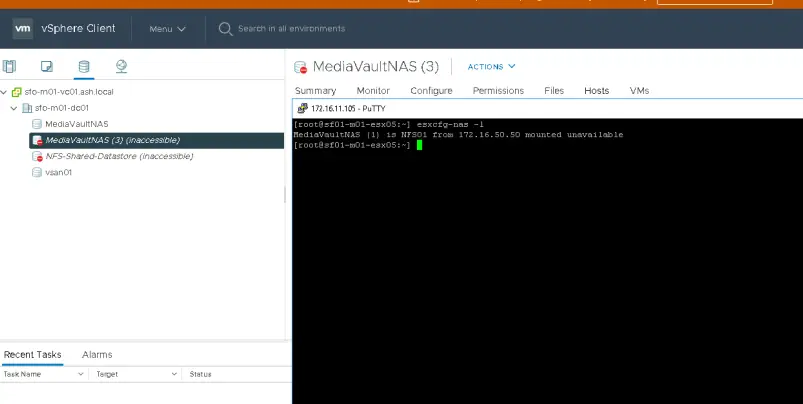
- Make a note of the NFS datastore name.
- Run this command to stop the SIOC service
- /etc/init.d/storageRM stop
- Click rescan all adapters by running esxcli storage core adapter rescan --all
- Run this command to restart the SIOC service:
- /etc/init.d/storageRM start
- Restart management agents on the host
- /etc/init.d/hostd restart
- /etc/init.d/vpxd restart
- Reboot the host to see if the path errors get fixed.
Verify all NFS datastores in esx inventory
[root@sfo01-m01-esx01:~] esxcli storage nfs list
Volume Name Host Share Accessible Mounted Read-Only isPE Hardware Acceleration
——————– ———— ————- ———- ——- ——— —– ———————
NFS-Shared-Datastore 172.16.50.50 /export/NFS01 true true false false Not Supported

Verify all file systems in esx inventory
[root@sfo01-m01-esx04:~] esxcli storage filesystem list

Remove a datastore from esx inventory
[root@sf01-m01-esx05:~] esxcli storage nfs remove -v NFS-Shared-Datastore
Rescan storage adapters
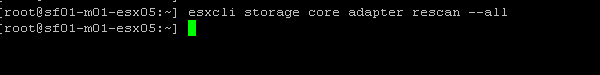
As per the above steps, this broken datastore “MediaVault” doesn’t appear in esx inventory at all.
The fix to the above issue is tweaking via the psql database on the Center.
https://kb.vmware.com/s/article/2147285
- Snapshot the vCenter server.
- Log into the VCSA as root via SSH or Console.
- Connect to the VCDB by running this command from the vCenter Server Appliance on 6.5/6.7/7.0 shellroot@sfo-m01-vc01 [ ~ ]
# /opt/vmware/vpostgres/current/bin/psql -d VCDB -U postgres
psql.bin (11.8 (VMware Postgres 11.8.0-16519916 release))
Type “help” for help.
VCDB=# SELECT id FROM vpx_entity WHERE name = ‘MediaVaultNAS’;
Note that Id
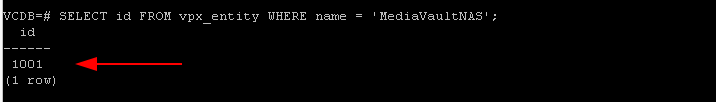
The Id of the datastore is 1005 and now we will need to find what connecting to that id.
VCDB=# SELECT * FROM vpx_ds_assignment WHERE ds_id=1001;

As per the above data, we have an object in the inventory that are still connected to this datastore
VCDB=# SELECT * FROM vpx_entity WHERE id=2007;

So its the CentosOS VM in here which is causing us issues, now we need to do is to remove the ID as shown
VCDB=# DELETE FROM vpx_ds_assignment WHERE ds_id=1001;
VCDB=# DELETE FROM vpx_datastore WHERE id=1001;
VCDB=# DELETE FROM vpx_vm_ds_space WHERE ds_id=1001;
VCDB=# exit

root@sfo-m01-vc01 [ ~ ]# reboot
Logon to vCenter and this time the zombie datastore will be gone from inventory