

This is a common issue that you would see on the ESXi host when the cluster has some odd issues going on. These usually stem from an incident such as a datastore running out of space, cluster settings not being able to withstand the SDRS/DRS configured settings or probably the NSX/VPXA/HOSTD agents on the host crashing, VMkernel MTU mismatch etc
A quick and easy way to fix this issue is just to disable DRS on the cluster and enable it back, this will most likely fix the odd issue.
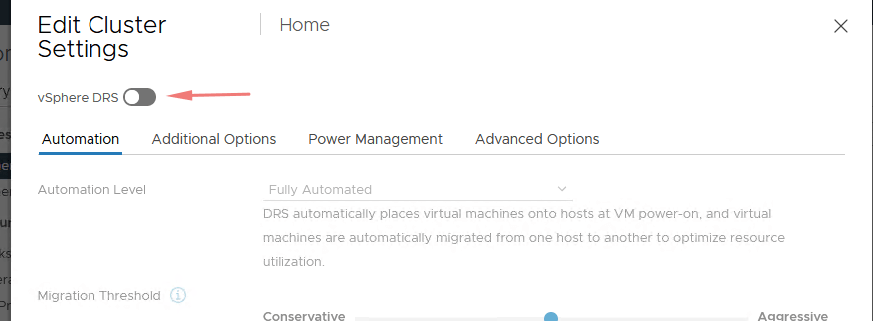
If the above fix hasn’t resolved the issue, then the other option is just to restart the management agents hostd & vpxa agents on the host
Step 1 – Enable SSH onto the ESXi host and just the below commands to restart Management agents in a host
/etc/init.d/hostd restart && /etc/init.d/vpxa restartStep 2 – Verify if services have started host and just the below commands
/etc/init.d/hostd status && /etc/init.d/vpxa statusStep 3 – If necessary, reset the management network on a specific VMkernel interface ( Optional step )
esxcli network ip interface set -e false -i vmk0
esxcli network ip interface set -e true -i vmk0Step 4 – Migrate all VMs from the host
Step 5- Place the host in maintenance mode
Step 6- Reboot the host to see if that fixes the issue
Step 7- Reboot the host to see if that fixes the issue
Step 8- Remove the ESXi/ESX host by dragging it out of the cluster.
Step 9- Add the host back into the cluster